Publications
-
Language Model Cascades: Token-Level Uncertainty And Beyond 2024To appear in ICLR 2024Recent advances in language models (LMs) have led to significant improvements in quality on complex NLP tasks, but at the expense of increased inference costs. A simple strategy to achieve more favorable cost-quality tradeoffs is cascading: here, a small model is invoked for most “easy” instances, while a few “hard” instances are deferred to the large model. While the principles underpinning effective cascading are well-studied for classification tasks — with deferral based on predicted class uncertainty favored theoretically and practically — a similar understanding is lacking for generative LM tasks. In this work, we initiate a systematic study of deferral rules for LM cascades. We begin by examining the natural extension of predicted class uncertainty to generative LM tasks, namely, the predicted sequence uncertainty. We show that this measure suffers from the length bias problem, either over- or under-emphasizing outputs based on their lengths. This is because LMs produce a sequence of uncertainty values, one for each output token; and moreover, the number of output tokens is variable across different examples. To mitigate the length bias, we propose to exploit the richer token-level uncertainty information implicit in generative LMs. We argue that naive predicted sequence uncertainty corresponds to a simple aggregation of these uncertainties. By contrast, we show that incorporating token-level uncertainty through learned post-hoc deferral rules can significantly outperform such simple aggregation strategies, via experiments on a range of natural language benchmarks with FLAN-T5 models. We further show that incorporating embeddings from the smaller model and intermediate layers of the larger model can give an additional boost in the overall cost-quality tradeoff.
@inproceedings{gupta2024language, title = {Language Model Cascades: Token-Level Uncertainty And Beyond}, author = {Gupta, Neha and Narasimhan, Harikrishna and Jitkrittum, Wittawat and Rawat, Ankit Singh and Menon, Aditya Krishna and Kumar, Sanjiv}, year = {2024}, url = {https://openreview.net/forum?id=KgaBScZ4VI}, wj_http = {https://openreview.net/forum?id=KgaBScZ4VI}, wj_note = {To appear in ICLR 2024} } -
Plugin estimators for selective classification with out-of-distribution detection 2024To appear in ICLR 2024Real-world classifiers can benefit from the option of abstaining from predicting on samples where they have low confidence. Such abstention is particularly useful on samples which are close to the learned decision boundary, or which are outliers with respect to the training sample. These settings have been the subject of extensive but disjoint study in the selective classification (SC) and out-of-distribution (OOD) detection literature. Recent work on selective classification with OOD detection (SCOD) has argued for the unified study of these problems; however, the formal underpinnings of this problem are still nascent, and existing techniques are heuristic in nature. In this paper, we propose new plugin estimators for SCOD that are theoretically grounded, effective, and generalise existing approaches from the SC and OOD detection literature. In the course of our analysis, we formally explicate how naïve use of existing SC and OOD detection baselines may be inadequate for SCOD. We empirically demonstrate that our approaches yields competitive SC and OOD detection trade-offs compared to common baselines.
@inproceedings{nara2024plugin, title = {Plugin estimators for selective classification with out-of-distribution detection}, author = {Narasimhan, Harikrishna and Menon, Aditya Krishna and Jitkrittum, Wittawat and Kumar, Sanjiv}, year = {2024}, url = {https://openreview.net/forum?id=DASh78rJ7g}, wj_http = {https://openreview.net/forum?id=DASh78rJ7g}, wj_note = {To appear in ICLR 2024} } -
Learning to Reject for Balanced Error and Beyond 2024To appear in ICLR 2024Learning to reject (L2R) is a classical problem where one seeks a classifier capable of abstaining on low-confidence samples. Most prior work on L2R has focused on minimizing the standard misclassification error. However, in many real-world applications, the label distribution is highly imbalanced, necessitating alternate evaluation metrics such as the balanced error or the worst-group error that enforce equitable performance across both the head and tail classes. In this paper, we establish that traditional L2R methods can be grossly sub-optimal for such metrics, and show that this is due to an intricate dependence in the objective between the label costs and the rejector. We then derive the form of the Bayes-optimal classifier and rejector for the balanced error, propose a novel plug-in approach to mimic this solution, and extend our results to general evaluation metrics. Through experiments on benchmark image classification tasks, we show that our approach yields better trade-offs in both the balanced and worst-group error compared to L2R baselines.
@inproceedings{nara2024learning, title = {Learning to Reject for Balanced Error and Beyond}, author = {Narasimhan, Harikrishna and Menon, Aditya Krishna and Jitkrittum, Wittawat and Gupta, Neha and Kumar, Sanjiv}, year = {2024}, url = {https://openreview.net/forum?id=ta26LtNq2r}, wj_http = {https://openreview.net/forum?id=ta26LtNq2r}, wj_note = {To appear in ICLR 2024} } -
On Bias-Variance Alignment in Deep Models 2024To appear in ICLR 2024Classical wisdom in machine learning holds that the generalization error can be decomposed into bias and variance, and these two terms exhibit a \emphtrade-off. However, in this paper, we show that for an ensemble of deep learning based classification models, bias and variance are \emphaligned at a sample level, where squared bias is approximately \emphequal to variance for correctly classified sample points. We present empirical evidence confirming this phenomenon in a variety of deep learning models and datasets. Moreover, we study this phenomenon from two theoretical perspectives: calibration and neural collapse. We first show theoretically that under the assumption that the models are well calibrated, we can observe the bias-variance alignment. Second, starting from the picture provided by the neural collapse theory, we show an approximate correlation between bias and variance.
@inproceedings{chen2024on, title = {On Bias-Variance Alignment in Deep Models}, author = {Chen, Lin and Lukasik, Michal and Jitkrittum, Wittawat and You, Chong and Kumar, Sanjiv}, year = {2024}, url = {https://openreview.net/forum?id=i2Phucne30}, wj_note = {To appear in ICLR 2024}, wj_http = {https://openreview.net/forum?id=i2Phucne30} } -
When Does Confidence-Based Cascade Deferral Suffice? NeurIPS 2023Cascades are a classical strategy to enable inference cost to vary adaptively across samples, wherein a sequence of classifiers are invoked in turn. A deferral rule determines whether to invoke the next classifier in the sequence, or to terminate prediction. One simple deferral rule employs the confidence of the current classifier, e.g., based on the maximum predicted softmax probability. Despite being oblivious to the structure of the cascade – e.g., not modelling the errors of downstream models – such confidence-based deferral often works remarkably well in practice. In this paper, we seek to better understand the conditions under which confidence-based deferral may fail, and when alternate deferral strategies can perform better. We first present a theoretical characterisation of the optimal deferral rule, which precisely characterises settings under which confidence-based deferral may suffer. We then study post-hoc deferral mechanisms, and demonstrate they can significantly improve upon confidence-based deferral in settings where (i) downstream models are specialists that only work well on a subset of inputs, (ii) samples are subject to label noise, and (iii) there is distribution shift between the train and test set.
@inproceedings{jitkrittum2023does, title = {When Does Confidence-Based Cascade Deferral Suffice?}, author = {Jitkrittum, Wittawat and Gupta, Neha and Menon, Aditya Krishna and Narasimhan, Harikrishna and Rawat, Ankit Singh and Kumar, Sanjiv}, booktitle = {NeurIPS}, year = {2023}, wj_http = {https://openreview.net/forum?id=4KZhZJSPYU} } -
A Kernel Stein Test for Comparing Latent Variable Models Journal of the Royal Statistical Society Series B: Statistical Methodology 2023We propose a kernel-based nonparametric test of relative goodness of fit, where the goal is to compare two models, both of which may have unobserved latent variables, such that the marginal distribution of the observed variables is intractable. The proposed test generalizes the recently proposed kernel Stein discrepancy (KSD) tests (Liu et al., Proceedings of the 33rd international conference on machine learning (pp. 276–284); Chwialkowski et al., (2016), In Proceedings of the 33rd international conference on machine learning (pp. 2606–2615); Yang et al., (2018), In Proceedings of the 35th international conference on machine learning (pp. 5561–5570)) to the case of latent variable models, a much more general class than the fully observed models treated previously. The new test, with a properly calibrated threshold, has a well-controlled type-I error. In the case of certain models with low-dimensional latent structures and high-dimensional observations, our test significantly outperforms the relative maximum mean discrepancy test, which is based on samples from the models and does not exploit the latent structure.
@article{kanagawa2023, author = {Kanagawa, Heishiro and Jitkrittum, Wittawat and Mackey, Lester and Fukumizu, Kenji and Gretton, Arthur}, title = {{A Kernel Stein Test for Comparing Latent Variable Models}}, journal = {Journal of the Royal Statistical Society Series B: Statistical Methodology}, volume = {85}, number = {3}, pages = {986-1011}, year = {2023}, month = may, issn = {1369-7412}, doi = {10.1093/jrsssb/qkad050}, url = {https://doi.org/10.1093/jrsssb/qkad050}, eprint = {https://academic.oup.com/jrsssb/article-pdf/85/3/986/50859865/qkad050.pdf}, wj_http = {https://academic.oup.com/jrsssb/article/85/3/986/7153413?login=false} } -
EmbedDistill: A Geometric Knowledge Distillation for Information Retrieval arXiv 2023
@misc{https://doi.org/10.48550/arxiv.2301.12005, doi = {10.48550/ARXIV.2301.12005}, url = {https://arxiv.org/abs/2301.12005}, author = {Kim, Seungyeon and Rawat, Ankit Singh and Zaheer, Manzil and Jayasumana, Sadeep and Sadhanala, Veeranjaneyulu and Jitkrittum, Wittawat and Menon, Aditya Krishna and Fergus, Rob and Kumar, Sanjiv}, title = {EmbedDistill: A Geometric Knowledge Distillation for Information Retrieval}, publisher = {arXiv}, booktitle = {arXiv}, year = {2023}, wj_http = {https://arxiv.org/abs/2301.12005} } -
Post-hoc estimators for learning to defer to an expert NeurIPS 2022Many practical settings allow a learner to defer predictions to one or more costly experts. For example, the learning to defer paradigm allows a learner to defer to a human expert, at some monetary cost. Similarly, the adaptive inference paradigm allows a base model to defer to one or more large models, at some computational cost. The goal in these settings is to learn classification and deferral mechanisms to optimise a suitable accuracy-cost tradeoff. To achieve this, a central issue studied in prior work is the design of a coherent loss function for both mechanisms. In this work, we demonstrate that existing losses have two subtle limitations: they can encourage underfitting when there is a high cost of deferring, and the deferral function can have a weak dependence on the base model predictions. To resolve these issues, we propose a post-hoc training scheme: we train a deferral function on top of a base model, with the objective of predicting to defer when the base model’s error probability exceeds the cost of the expert model. This may be viewed as applying a partial surrogate to the ideal deferral loss, which can lead to a tighter approximation and thus better performance. Empirically, we verify the efficacy of post-hoc training on benchmarks for learning to defer and adaptive inference.
@inproceedings{narasimhanpost, title = {Post-hoc estimators for learning to defer to an expert}, author = {Narasimhan, Harikrishna and Jitkrittum, Wittawat and Menon, Aditya Krishna and Rawat, Ankit Singh and Kumar, Sanjiv}, booktitle = {NeurIPS}, year = {2022}, wj_http = {https://openreview.net/forum?id=_jg6Sf6tuF7} } -
A Sketch Is Worth a Thousand Words: Image Retrieval with Text and Sketch European Conference on Computer Vision 2022We address the problem of retrieving in-the-wild images with both a sketch and a text query. We present TASK-former (Text And SKetch transformer), an end-to-end trainable model for image retrieval using a text description and a sketch as input. We argue that both input modalities complement each other in a manner that cannot be achieved easily by either one alone. TASK-former follows the late-fusion dual-encoder approach, similar to CLIP, which allows efficient and scalable retrieval since the retrieval set can be indexed independently of the queries. We empirically demonstrate that using an input sketch (even a poorly drawn one) in addition to text considerably increases retrieval recall compared to traditional text-based image retrieval. To evaluate our approach, we collect 5,000 hand-drawn sketches for images in the test set of the COCO dataset. The collected sketches are available a https://janesjanes.github.io/tsbir/.
@inproceedings{sangkloy2022, title = {A Sketch Is Worth a Thousand Words: Image Retrieval with Text and Sketch}, author = {Sangkloy, Patsorn and Jitkrittum, Wittawat and Yang, Diyi and Hays, James}, booktitle = {European Conference on Computer Vision}, year = {2022}, wj_http = {https://arxiv.org/abs/2208.03354}, wj_code = {https://janesjanes.github.io/tsbir/} } -
Discussion of Multiscale Fisher’s Independence Test for Multivariate Dependence Biometrika 2022We discuss how MultiFIT, the Multiscale Fisher’s Independence Test for Multivariate Dependence proposed by Gorsky and Ma (2022), compares to existing linear-time kernel tests based on the Hilbert-Schmidt independence criterion (HSIC). We highlight the fact that the levels of the kernel tests at any finite sample size can be controlled exactly, as it is the case with the level of MultiFIT. In our experiments, we observe some of the performance limitations of MultiFIT in terms of test power.
@article{schrab2022discussion, title = {Discussion of Multiscale Fisher's Independence Test for Multivariate Dependence}, author = {Schrab, Antonin and Jitkrittum, Wittawat and Szab{\'o}, Zolt{\'a}n and Sejdinovic, Dino and Gretton, Arthur}, journal = {Biometrika}, year = {2022}, wj_http = {https://arxiv.org/abs/2206.11142} } -
ELM: Embedding and Logit Margins for Long-Tail Learning 2022Long-tail learning is the problem of learning under skewed label distributions, which pose a challenge for standard learners. Several recent approaches for the problem have proposed enforcing a suitable margin in logit space. Such techniques are intuitive analogues of the guiding principle behind SVMs, and are equally applicable to linear models and neural models. However, when applied to neural models, such techniques do not explicitly control the geometry of the learned embeddings. This can be potentially sub-optimal, since embeddings for tail classes may be diffuse, resulting in poor generalization for these classes. We present Embedding and Logit Margins (ELM), a unified approach to enforce margins in logit space, and regularize the distribution of embeddings. This connects losses for long-tail learning to proposals in the literature on metric embedding, and contrastive learning. We theoretically show that minimising the proposed ELM objective helps reduce the generalisation gap. The ELM method is shown to perform well empirically, and results in tighter tail class embeddings.
@misc{elm2022, doi = {10.48550/ARXIV.2204.13208}, url = {https://arxiv.org/abs/2204.13208}, author = {Jitkrittum, Wittawat and Menon, Aditya Krishna and Rawat, Ankit Singh and Kumar, Sanjiv}, keywords = {Machine Learning (cs.LG), Machine Learning (stat.ML), FOS: Computer and information sciences, FOS: Computer and information sciences}, title = {ELM: Embedding and Logit Margins for Long-Tail Learning}, publisher = {arXiv}, year = {2022}, copyright = {Creative Commons Attribution 4.0 International}, wj_http = {https://arxiv.org/abs/2204.13208} } -
A Witness Two-Sample Test Proceedings of The 25th International Conference on Artificial Intelligence and Statistics 2022The Maximum Mean Discrepancy (MMD) has been the state-of-the-art nonparametric test for tackling the two-sample problem. Its statistic is given by the difference in expectations of the witness function, a real-valued function defined as a weighted sum of kernel evaluations on a set of basis points. Typically the kernel is optimized on a training set, and hypothesis testing is performed on a separate test set to avoid overfitting (i.e., control type-I error). That is, the test set is used to simultaneously estimate the expectations and define the basis points, while the training set only serves to select the kernel and is discarded. In this work, we propose to use the training data to also define the weights and the basis points for better data efficiency. We show that 1) the new test is consistent and has a well-controlled type-I error; 2) the optimal witness function is given by a precision-weighted mean in the reproducing kernel Hilbert space associated with the kernel; and 3) the test power of the proposed test is comparable or exceeds that of the MMD and other modern tests, as verified empirically on challenging synthetic and real problems (e.g., Higgs data).
@inproceedings{pmlr-v151-kubler22a, title = { A Witness Two-Sample Test }, author = {K\"ubler, Jonas M. and Jitkrittum, Wittawat and Sch\"olkopf, Bernhard and Muandet, Krikamol}, booktitle = {Proceedings of The 25th International Conference on Artificial Intelligence and Statistics}, pages = {1403--1419}, year = {2022}, editor = {Camps-Valls, Gustau and Ruiz, Francisco J. R. and Valera, Isabel}, volume = {151}, series = {Proceedings of Machine Learning Research}, month = {28--30 Mar}, publisher = {PMLR}, pdf = {https://proceedings.mlr.press/v151/kubler22a/kubler22a.pdf}, url = {https://proceedings.mlr.press/v151/kubler22a.html}, wj_http = {https://arxiv.org/abs/2102.05573}, wj_talk = {https://slideslive.ch/38980440/a-witness-twosample-test?ref=speaker-17291}, wj_code = {https://github.com/jmkuebler/wits-test} } -
ABCDP: Approximate Bayesian Computation with Differential Privacy Entropy 2021We developed a novel approximate Bayesian computation (ABC) framework, ABCDP, which produces differentially private (DP) and approximate posterior samples. Our framework takes advantage of the sparse vector technique (SVT), widely studied in the differential privacy literature. SVT incurs the privacy cost only when a condition (whether a quantity of interest is above/below a threshold) is met. If the condition is sparsely met during the repeated queries, SVT can drastically reduce the cumulative privacy loss, unlike the usual case where every query incurs the privacy loss. In ABC, the quantity of interest is the distance between observed and simulated data, and only when the distance is below a threshold can we take the corresponding prior sample as a posterior sample. Hence, applying SVT to ABC is an organic way to transform an ABC algorithm to a privacy-preserving variant with minimal modification, but yields the posterior samples with a high privacy level. We theoretically analyzed the interplay between the noise added for privacy and the accuracy of the posterior samples. We apply ABCDP to several data simulators and show the efficacy of the proposed framework.
@article{abcdp2021, author = {Park, Mijung and Vinaroz, Margarita and Jitkrittum, Wittawat}, title = {ABCDP: Approximate Bayesian Computation with Differential Privacy}, journal = {Entropy}, volume = {23}, year = {2021}, number = {8}, article-number = {961}, url = {https://www.mdpi.com/1099-4300/23/8/961}, issn = {1099-4300}, doi = {10.3390/e23080961}, wj_http = {https://www.mdpi.com/1099-4300/23/8/961}, wj_code = {https://github.com/ParkLabML/ABCDP} } -
Disentangling Sampling and Labeling Bias for Learning in Large-Output Spaces ICML 2021Negative sampling schemes enable efficient training given a large number of classes, by offering a means to approximate a computationally expensive loss function that takes all labels into account. In this paper, we present a new connection between these schemes and loss modification techniques for countering label imbalance. We show that different negative sampling schemes implicitly trade-off performance on dominant versus rare labels. Further, we provide a unified means to explicitly tackle both sampling bias, arising from working with a subset of all labels, and labeling bias, which is inherent to the data due to label imbalance. We empirically verify our findings on long-tail classification and retrieval benchmarks.
@inproceedings{rawat2021, title = {Disentangling Sampling and Labeling Bias for Learning in Large-Output Spaces}, author = {Rawat, Ankit Singh and Menon, Aditya Krishna and Jitkrittum, Wittawat and Jayasumana, Sadeep and Yu, Felix X. and Reddi, Sashank and Kumar, Sanjiv}, booktitle = {ICML}, year = {2021}, wj_http = {https://arxiv.org/abs/2105.05736} } -
Kernel Distributionally Robust Optimization: Generalized Duality Theorem and Stochastic Approximation Proceedings of The 24th International Conference on Artificial Intelligence and Statistics 2021We propose kernel distributionally robust optimization (Kernel DRO) using insights from the robust optimization theory and functional analysis. Our method uses reproducing kernel Hilbert spaces (RKHS) to construct a wide range of convex ambiguity sets, which can be generalized to sets based on integral probability metrics and finite-order moment bounds. This perspective unifies multiple existing robust and stochastic optimization methods. We prove a theorem that generalizes the classical duality in the mathematical problem of moments. Enabled by this theorem, we reformulate the maximization with respect to measures in DRO into the dual program that searches for RKHS functions. Using universal RKHSs, the theorem applies to a broad class of loss functions, lifting common limitations such as polynomial losses and knowledge of the Lipschitz constant. We then establish a connection between DRO and stochastic optimization with expectation constraints. Finally, we propose practical algorithms based on both batch convex solvers and stochastic functional gradient, which apply to general optimization and machine learning tasks.
@inproceedings{zhu2021kernel, title = { Kernel Distributionally Robust Optimization: Generalized Duality Theorem and Stochastic Approximation }, author = {Zhu, Jia-Jie and Jitkrittum, Wittawat and Diehl, Moritz and Sch{\"o}lkopf, Bernhard}, booktitle = {Proceedings of The 24th International Conference on Artificial Intelligence and Statistics}, pages = {280--288}, year = {2021}, editor = {Banerjee, Arindam and Fukumizu, Kenji}, volume = {130}, series = {Proceedings of Machine Learning Research}, month = {13--15 Apr}, publisher = {PMLR}, pdf = {http://proceedings.mlr.press/v130/zhu21a/zhu21a.pdf}, url = {http://proceedings.mlr.press/v130/zhu21a.html}, wj_http = {http://proceedings.mlr.press/v130/zhu21a.html}, wj_code = {https://github.com/jj-zhu/kdro} } -
More Powerful Selective Kernel Tests for Feature Selection Proceedings of The 23rd International Conference on Artificial Intelligence and Statistics 2020Refining one’s hypotheses in light of data is a commonplace scientific practice, however,this approach introduces selection bias and can lead to specious statisticalanalysis.One approach of addressing this phenomena is via conditioning on the selection procedure, i.e., how we have used the data to generate our hypotheses, and prevents information to be used again after selection.Many selective inference (a.k.a. post-selection inference) algorithms typically take this approach but will “over-condition”for sake of tractability. While this practice obtains well calibrated p-values,it can incur a major loss in power. In our work, we extend two recent proposals for selecting features using the Maximum Mean Discrepancyand Hilbert Schmidt Independence Criterion to condition on the minimalconditioning event. We show how recent advances inmultiscale bootstrap makesthis possible and demonstrate our proposal over a range of synthetic and real world experiments.Our results show that our proposed test is indeed more powerful in most scenarios.
@inproceedings{pmlr-v108-lim20a, title = {More Powerful Selective Kernel Tests for Feature Selection}, author = {Lim, Jen Ning and Yamada, Makoto and Jitkrittum, Wittawat and Terada, Yoshikazu and Matsui, Shigeyuki and Shimodaira, Hidetoshi}, booktitle = {Proceedings of The 23rd International Conference on Artificial Intelligence and Statistics}, pages = {820--830}, year = {2020}, editor = {Chiappa, Silvia and Calandra, Roberto}, volume = {108}, series = {Proceedings of Machine Learning Research}, address = {Online}, month = {26--28 Aug}, publisher = {PMLR}, pdf = {http://proceedings.mlr.press/v108/lim20a/lim20a.pdf}, url = {http://proceedings.mlr.press/v108/lim20a.html}, wj_http = {http://proceedings.mlr.press/v108/lim20a.html}, wj_code = {https://github.com/jenninglim/multiscale-features} } -
Learning Kernel Tests Without Data Splitting NeurIPS 2020Modern large-scale kernel-based tests such as maximum mean discrepancy (MMD) and kernelized Stein discrepancy (KSD) optimize kernel hyperparameters on a held-out sample via data splitting to obtain the most powerful test statistics. While data splitting results in a tractable null distribution, it suffers from a reduction in test power due to smaller test sample size. Inspired by the selective inference framework, we propose an approach that enables learning the hyperparameters and testing on the full sample without data splitting. Our approach can correctly calibrate the test in the presence of such dependency, and yield a test threshold in closed form. At the same significance level, our approach’s test power is empirically larger than that of the data-splitting approach, regardless of its split proportion.
@incollection{kbler2020learning, title = {Learning Kernel Tests Without Data Splitting}, booktitle = {NeurIPS}, author = {K\"{u}bler, Jonas M. and Jitkrittum, Wittawat and Sch\"{o}lkopf, Bernhard and Muandet, Krikamol}, year = {2020}, wj_http = {https://arxiv.org/abs/2006.02286}, wj_code = {https://github.com/MPI-IS/tests-wo-splitting}, wj_talk = {https://nips.cc/virtual/2020/protected/poster_44f683a84163b3523afe57c2e008bc8c.html} } -
Worst-Case Risk Quantification under Distributional Ambiguity using Kernel Mean Embedding in Moment Problem 2020 59th IEEE Conference on Decision and Control (CDC) 2020In order to anticipate rare and impactful events, we propose to quantify the worst-case risk under distributional ambiguity using a recent development in kernel methods - the kernel mean embedding. Specifically, we formulate the generalized moment problem whose ambiguity set (i.e., the moment constraint) is described by constraints in the associated reproducing kernel Hilbert space in a nonparametric manner. We then present the tractable approximation and its theoretical justification. As a concrete application, we numerically test the proposed method in characterizing the worst-case constraint violation probability in the context of a constrained stochastic control system.
@inproceedings{9303938, author = {Zhu, Jia-Jie and Jitkrittum, Wittawat and Diehl, Moritz and Schölkopf, Bernhard}, booktitle = {2020 59th IEEE Conference on Decision and Control (CDC)}, title = {Worst-Case Risk Quantification under Distributional Ambiguity using Kernel Mean Embedding in Moment Problem}, year = {2020}, volume = {}, number = {}, pages = {3457-3463}, doi = {10.1109/CDC42340.2020.9303938}, wj_http = {https://arxiv.org/abs/2004.00166} } -
Testing Goodness of Fit of Conditional Density Models with Kernels The Conference on Uncertainty in Artificial Intelligence (UAI) 2020
abstract paper bib code talk slides
We propose two nonparametric statistical tests of goodness of fit for conditional distributions: given a conditional probability density function p(y|x) and a joint sample, decide whether the sample is drawn from p(y|x)rx(x) for some density rx. Our tests, formulated with a Stein operator, can be applied to any differentiable conditional density model, and require no knowledge of the normalizing constant. We show that 1) our tests are consistent against any fixed alternative conditional model; 2) the statistics can be estimated easily, requiring no density estimation as an intermediate step; and 3) our second test offers an interpretable test result providing insight on where the conditional model does not fit well in the domain of the covariate. We demonstrate the interpretability of our test on a task of modeling the distribution of New York City’s taxi drop-off location given a pick-up point. To our knowledge, our work is the first to propose such conditional goodness-of-fit tests that simultaneously have all these desirable properties.@conference{jitkrittum2020testing, title = {Testing Goodness of Fit of Conditional Density Models with Kernels}, author = {Jitkrittum, Wittawat and Kanagawa, Heishiro and Sch\"{o}lkopf, Bernhard}, booktitle = {The Conference on Uncertainty in Artificial Intelligence (UAI)}, year = {2020}, url = {https://arxiv.org/abs/2002.10271}, wj_http = {https://arxiv.org/abs/2002.10271}, wj_code = {https://github.com/wittawatj/kernel-cgof}, wj_slides = {https://docs.google.com/presentation/d/14I4ndHux8C3ImRzAqmNPVLmLQkw8wZQucMMTZrACUXk/edit?usp=sharing}, wj_talk = {https://www.youtube.com/watch?v=RGz6LfZwqDA&list=PLTrdDEfEeShmhkbbCtmaPst7f7CFll0kc&index=95} } -
Kernel Conditional Moment Test via Maximum Moment Restriction The Conference on Uncertainty in Artificial Intelligence (UAI) 2020We propose a new family of specification tests called kernel conditional moment (KCM) tests. Our tests are built on conditional moment embeddings (CMME)—a novel representation of conditional moment restrictions in a reproducing kernel Hilbert space (RKHS). After transforming the conditional moment restrictions into a continuum of unconditional counterparts, the test statistic is defined as the maximum moment restriction within the unit ball of the RKHS. We show that the CMME fully characterizes the original conditional moment restrictions, leading to consistency in both hypothesis testing and parameter estimation. The proposed test also has an analytic expression that is easy to compute as well as closed-form asymptotic distributions. Our empirical studies show that the KCM test has a promising finite-sample performance compared to existing tests.
@conference{mmrtest2020, author = {{Muandet}, Krikamol and {Jitkrittum}, Wittawat and {K{\"u}bler}, Jonas}, booktitle = {The Conference on Uncertainty in Artificial Intelligence (UAI)}, title = {Kernel Conditional Moment Test via Maximum Moment Restriction}, year = {2020}, wj_http = {https://arxiv.org/abs/2002.09225}, wj_code = {https://github.com/krikamol/kcm-test}, wj_talk = {https://www.youtube.com/watch?v=XkkXCXbsRpY} } -
Kernel Stein Tests for Multiple Model Comparison NeurIPS 2019
abstract paper bib poster code
We address the problem of nonparametric multiple model comparison: given l candidate models, decide whether each candidate is as good as the best one(s) in the list (negative), or worse (positive). We propose two statistical tests, each controlling a different notion of decision errors. The first test, building on the post selection inference framework, provably controls the fraction of best models that are wrongly declared worse (false positive rate). The second test is based on multiple correction, and controls the fraction of the models declared worse that are in fact as good as the best (false discovery rate). We prove that under some conditions the first test can yield a higher true positive rate than the second. Experimental results on toy and real (CelebA, Chicago Crime data) problems show that the two tests have high true positive rates with well-controlled error rates. By contrast, the naive approach of choosing the model with the lowest score without correction leads to a large number of false positives.@incollection{NIPS2019_8496, title = {Kernel Stein Tests for Multiple Model Comparison}, author = {Lim, Jen Ning and Yamada, Makoto and Sch\"{o}lkopf, Bernhard and Jitkrittum, Wittawat}, booktitle = {NeurIPS}, editor = {Wallach, H. and Larochelle, H. and Beygelzimer, A. and d\textquotesingle Alch\'{e}-Buc, F. and Fox, E. and Garnett, R.}, pages = {2240--2250}, year = {2019}, publisher = {Curran Associates, Inc.}, url = {http://papers.nips.cc/paper/8496-kernel-stein-tests-for-multiple-model-comparison.pdf}, wj_http = {https://arxiv.org/abs/1910.12252}, wj_code = {https://github.com/jenninglim/model-comparison-test}, wj_poster = {https://github.com/jenninglim/model-comparison-test/raw/master/docs/poster.pdf} } -
Fisher Efficient Inference of Intractable Models NeurIPS 2019
abstract paper bib code slides
Maximum Likelihood Estimators (MLE) has many good properties. For example, the asymptotic variance of MLE solution attains equality of the asymptotic Cramér-Rao lower bound (efficiency bound), which is the minimum possible variance for an unbiased estimator. However, obtaining such MLE solution requires calculating the likelihood function which may not be tractable due to the normalization term of the density model. In this paper, we derive a Discriminative Likelihood Estimator (DLE) from the Kullback-Leibler divergence minimization criterion implemented via density ratio estimation procedure and Stein operator. We study the problem of model inference using DLE. We prove its consistency and show the asymptotic variance of its solution can also attain the equality of the efficiency bound under mild regularity conditions. We also propose a dual formulation of DLE which can be easily optimized. Numerical studies validate our asymptotic theorems and we give an example where DLE successfully estimates an intractable model constructed using a pre-trained deep neural network.@incollection{NIPS2019_9083, title = {Fisher Efficient Inference of Intractable Models}, author = {Liu, Song and Kanamori, Takafumi and Jitkrittum, Wittawat and Chen, Yu}, booktitle = {NeurIPS}, editor = {Wallach, H. and Larochelle, H. and Beygelzimer, A. and d\textquotesingle Alch\'{e}-Buc, F. and Fox, E. and Garnett, R.}, pages = {8790--8800}, year = {2019}, publisher = {Curran Associates, Inc.}, url = {http://papers.nips.cc/paper/9083-fisher-efficient-inference-of-intractable-models.pdf}, wj_http = {https://arxiv.org/abs/1805.07454}, wj_code = {https://github.com/anewgithubname/Stein-Density-Ratio-Estimation}, wj_slides = {https://github.com/lamfeeling/Stein-Density-Ratio-Estimation/blob/master/slides.pdf} } -
Generate Semantically Similar Images with Kernel Mean Matching Women in Computer Vision Workshop, CVPR 2019Oral presentation. 6 out of 64 accepted papers.
@misc{cagan_wicv2019, author = {Jitkrittum, Wittawat and Sangkloy, Patsorn and Gondal, Muhammad Waleed and Raj, Amit and Hays, James and {Sch{\"o}lkopf}, Bernhard}, title = {Generate Semantically Similar Images with Kernel Mean Matching}, howpublished = {Women in Computer Vision Workshop, CVPR}, year = {2019}, note = {The first two authors contributed equally. }, wj_http = {/assets/papers/cagan_wicv2019.pdf}, wj_highlight = {Oral presentation. 6 out of 64 accepted papers.}, wj_code = {https://github.com/wittawatj/cadgan} } -
Kernel Mean Matching for Content Addressability of GANs ICML 2019Long oral presentation
abstract paper bib poster code talk slides
We propose a novel procedure which adds "content-addressability" to any given unconditional implicit model e.g., a generative adversarial network (GAN). The procedure allows users to control the generative process by specifying a set (arbitrary size) of desired examples based on which similar samples are generated from the model. The proposed approach, based on kernel mean matching, is applicable to any generative models which transform latent vectors to samples, and does not require retraining of the model. Experiments on various high-dimensional image generation problems (CelebA-HQ, LSUN bedroom, bridge, tower) show that our approach is able to generate images which are consistent with the input set, while retaining the image quality of the original model. To our knowledge, this is the first work that attempts to construct, at test time, a content-addressable generative model from a trained marginal model.@inproceedings{cagan_icml2019, author = {Jitkrittum, Wittawat and Sangkloy, Patsorn and Gondal, Muhammad Waleed and Raj, Amit and Hays, James and {Sch{\"o}lkopf}, Bernhard}, title = {Kernel Mean Matching for Content Addressability of {GANs}}, booktitle = {ICML}, year = {2019}, note = {The first two authors contributed equally.}, wj_http = {https://arxiv.org/abs/1905.05882}, wj_code = {https://github.com/wittawatj/cadgan}, wj_poster = {/assets/poster/cadgan_poster_icml2019.pdf}, wj_slides = {https://docs.google.com/presentation/d/1XdsSP7jji2QB_tZf8QAYCJhs6QzGDmR_BLmOHLFCMqY/edit?usp=sharing}, wj_talk = {https://slideslive.com/38917639/applications-computer-vision}, wj_highlight = {Long oral presentation} } -
Kernel-Guided Training of Implicit Generative Models with Stability Guarantees ArXiv 2019Modern implicit generative models such as generative adversarial networks (GANs) are generally known to suffer from issues such as instability, uninterpretability, and difficulty in assessing their performance. If we see these implicit models as dynamical systems, some of these issues are caused by being unable to control their behavior in a meaningful way during the course of training. In this work, we propose a theoretically grounded method to guide the training trajectories of GANs by augmenting the GAN loss function with a kernel-based regularization term that controls local and global discrepancies between the model and true distributions. This control signal allows us to inject prior knowledge into the model. We provide theoretical guarantees on the stability of the resulting dynamical system and demonstrate different aspects of it via a wide range of experiments.
@article{witness_gan_rkhs2019, author = {{Mehrjou}, Arash and {Jitkrittum}, Wittawat and {Muandet}, Krikamol and {Sch{\"o}lkopf}, Bernhard}, title = {{Kernel-Guided Training of Implicit Generative Models with Stability Guarantees}}, journal = {ArXiv}, keywords = {Computer Science - Machine Learning, Statistics - Machine Learning}, year = {2019}, month = jan, eid = {arXiv:1901.09206}, eprint = {1901.09206}, primaryclass = {cs.LG}, wj_http = {https://arxiv.org/abs/1901.09206} } -
Informative Features for Model Comparison NeurIPS 2018
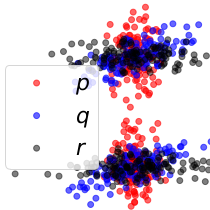 A linear-time test of relative goodness of fit of two models on a dataset. The test can produce evidence indicating where one model is better than the other. Applicable to implicit models such as GANs.
A linear-time test of relative goodness of fit of two models on a dataset. The test can produce evidence indicating where one model is better than the other. Applicable to implicit models such as GANs.abstract paper bib poster code
Given two candidate models, and a set of target observations, we address the problem of measuring the relative goodness of fit of the two models. We propose two new statistical tests which are nonparametric, computationally efficient (runtime complexity is linear in the sample size), and interpretable. As a unique advantage, our tests can produce a set of examples (informative features) indicating the regions in the data domain where one model fits significantly better than the other. In a real-world problem of comparing GAN models, the test power of our new test matches that of the state-of-the-art test of relative goodness of fit, while being one order of magnitude faster.@inproceedings{jitkrittum_kmod2018, title = {Informative Features for Model Comparison}, author = {Jitkrittum, Wittawat and Kanagawa, Heishiro and Sangkloy, Patsorn and Hays, James and Sch\"{o}lkopf, Bernhard and Gretton, Arthur}, booktitle = {NeurIPS}, year = {2018}, wj_http = {https://arxiv.org/abs/1810.11630}, wj_code = {https://github.com/wittawatj/kernel-mod}, wj_poster = {/assets/poster/kmod_nips2018_poster.pdf}, wj_img = {cover_nips2018.png}, wj_summary = { A linear-time test of relative goodness of fit of two models on a dataset. The test can produce evidence indicating where one model is better than the other. Applicable to implicit models such as GANs. } } -
Large Sample Analysis of the Median Heuristic ArXiv 2018In kernel methods, the median heuristic has been widely used as a way of setting the bandwidth of RBF kernels. While its empirical performances make it a safe choice under many circumstances, there is little theoretical understanding of why this is the case. Our aim in this paper is to advance our understanding of the median heuristic by focusing on the setting of kernel two-sample test. We collect new findings that may be of interest for both theoreticians and practitioners. In theory, we provide a convergence analysis that shows the asymptotic normality of the bandwidth chosen by the median heuristic in the setting of kernel two-sample test. Systematic empirical investigations are also conducted in simple settings, comparing the performances based on the bandwidths chosen by the median heuristic and those by the maximization of test power.
@article{median_heu_2018, author = {{Garreau}, Damien and {Jitkrittum}, Wittawat and {Kanagawa}, Motonobu}, title = {Large Sample Analysis of the Median Heuristic}, journal = {ArXiv}, eprint = {1707.07269}, keywords = {Mathematics - Statistics Theory, Statistics - Machine Learning, 62E20, 62G30}, year = {2018}, wj_http = {https://arxiv.org/abs/1707.07269} } -
A Linear-Time Kernel Goodness-of-Fit Test NeurIPS 2017NeurIPS 2017 Best paper. 3 out of 3240 submissions.
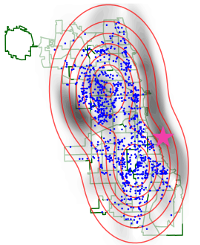 A linear-time test of goodness of fit of an unnormalized density function on a dataset. The test can produce evidence indicating where (in the data domain) the model does not fit well.
A linear-time test of goodness of fit of an unnormalized density function on a dataset. The test can produce evidence indicating where (in the data domain) the model does not fit well.abstract paper bib poster code talk slides
We propose a novel adaptive test of goodness-of-fit, with computational cost linear in the number of samples. We learn the test features that best indicate the differences between observed samples and a reference model, by minimizing the false negative rate. These features are constructed via Stein’s method, meaning that it is not necessary to compute the normalising constant of the model. We analyse the asymptotic Bahadur efficiency of the new test, and prove that under a mean-shift alternative, our test always has greater relative efficiency than a previous linear-time kernel test, regardless of the choice of parameters for that test. In experiments, the performance of our method exceeds that of the earlier linear-time test, and matches or exceeds the power of a quadratic-time kernel test. In high dimensions and where model structure may be exploited, our goodness of fit test performs far better than a quadratic-time two-sample test based on the Maximum Mean Discrepancy, with samples drawn from the model.@inproceedings{jitkrittum_linear-time_2017, title = {A Linear-Time Kernel Goodness-of-Fit Test}, url = {http://arxiv.org/abs/1705.07673}, booktitle = {NeurIPS}, author = {Jitkrittum, Wittawat and Xu, Wenkai and Szabo, Zoltan and Fukumizu, Kenji and Gretton, Arthur}, year = {2017}, wj_img = {cover_nips2017.png}, wj_summary = { A linear-time test of goodness of fit of an unnormalized density function on a dataset. The test can produce evidence indicating where (in the data domain) the model does not fit well. }, wj_http = {http://arxiv.org/abs/1705.07673}, wj_code = {https://github.com/wittawatj/kernel-gof}, wj_poster = {/assets/poster/kgof_nips2017_poster.pdf}, wj_slides = {/assets/talks/kgof_nips2017_oral.pdf}, wj_talk = {https://www.facebook.com/nipsfoundation/videos/1553635538061013/}, wj_highlight = {NeurIPS 2017 Best paper. 3 out of 3240 submissions.} } -
Kernel-Based Distribution Features for Statistical Tests and Bayesian Inference 2017My PhD Thesis. Gatsby Unit, University College London.
@phdthesis{phdthesis2017, author = {Jitkrittum, Wittawat}, title = {Kernel-Based Distribution Features for Statistical Tests and {Bayesian} Inference}, school = {University College London}, year = {2017}, month = nov, url = {http://discovery.ucl.ac.uk/10037987/}, wj_http = {http://discovery.ucl.ac.uk/10037987/}, wj_highlight = {My PhD Thesis. Gatsby Unit, University College London.} } -
An Adaptive Test of Independence with Analytic Kernel Embeddings ICML 2017
abstract paper bib poster code talk slides
A new computationally efficient dependence measure, and an adaptive statistical test of independence, are proposed. The dependence measure is the difference between analytic embeddings of the joint distribution and the product of the marginals, evaluated at a finite set of locations (features). These features are chosen so as to maximize a lower bound on the test power, resulting in a test that is data-efficient, and that runs in linear time (with respect to the sample size n). The optimized features can be interpreted as evidence to reject the null hypothesis, indicating regions in the joint domain where the joint distribution and the product of the marginals differ most. Consistency of the independence test is established, for an appropriate choice of features. In real-world benchmarks, independence tests using the optimized features perform comparably to the state-of-the-art quadratic-time HSIC test, and outperform competing O(n) and O(n log n) tests.@inproceedings{pmlr-v70-jitkrittum17a, title = {An Adaptive Test of Independence with Analytic Kernel Embeddings}, author = {Jitkrittum, Wittawat and Szab{\'o}, Zolt{\'a}n and Gretton, Arthur}, booktitle = {ICML}, year = {2017}, editor = {Precup, Doina and Teh, Yee Whye}, volume = {70}, url = {http://proceedings.mlr.press/v70/jitkrittum17a.html}, wj_http = {http://proceedings.mlr.press/v70/jitkrittum17a.html}, wj_code = {https://github.com/wittawatj/fsic-test}, wj_slides = {/assets/talks/fsic_icml2017_oral.pdf}, wj_talk = {https://vimeo.com/255244123}, wj_poster = {/assets/poster/fsic_icml2017_poster.pdf} } -
Cognitive Bias in Ambiguity Judgements: Using Computational Models to Dissect the Effects of Mild Mood Manipulation in Humans PLOS ONE 2016
@article{iigaya2016, title = {Cognitive Bias in Ambiguity Judgements: Using Computational Models to Dissect the Effects of Mild Mood Manipulation in Humans}, author = {Iigaya, Kiyohito and Jolivald, Aurelie and Jitkrittum, Wittawat and Gilchrist, Iain and Dayan, Peter and Paul, Elizabeth and Mendl, Michael}, year = {2016}, month = oct, journal = {PLOS ONE}, issn = {1932-6203}, publisher = {Public Library of Science}, wj_http = {http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0165840} } -
Interpretable Distribution Features with Maximum Testing Power NeurIPS 2016Oral presentation. 1.8% of total submission.
abstract paper bib poster code talk slides
Two semimetrics on probability distributions are proposed, given as the sum of differences of expectations of analytic functions evaluated at spatial or frequency locations (i.e, features). The features are chosen so as to maximize the distinguishability of the distributions, by optimizing a lower bound on test power for a statistical test using these features. The result is a parsimonious and interpretable indication of how and where two distributions differ locally. An empirical estimate of the test power criterion converges with increasing sample size, ensuring the quality of the returned features. In real-world benchmarks on high-dimensional text and image data, linear-time tests using the proposed semimetrics achieve comparable performance to the state-of-the-art quadratic-time maximum mean discrepancy test, while returning human-interpretable features that explain the test results.@inproceedings{fotest2016, author = {Jitkrittum, Wittawat and Szab\'{o}, Zolt\'{a}n and Chwialkowski, Kacper and Gretton, Arthur}, title = {Interpretable Distribution Features with Maximum Testing Power}, booktitle = {NeurIPS}, year = {2016}, url = {http://papers.nips.cc/paper/6148-interpretable-distribution-features-with-maximum-testing-power}, wj_http = {http://papers.nips.cc/paper/6148-interpretable-distribution-features-with-maximum-testing-power}, wj_poster = {/assets/poster/fotest_poster.pdf}, wj_code = {https://github.com/wittawatj/interpretable-test}, wj_talk = {https://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Interpretable-Distribution-Features-with-Maximum-Testing-Power}, wj_slides = {/assets/talks/fotest_oral.pdf}, wj_highlight = {Oral presentation. 1.8\% of total submission.} } -
K2-ABC: Approximate Bayesian Computation with Infinite Dimensional Summary Statistics via Kernel Embeddings AISTATS 2016Oral presentation. 6.5% of total submissions.
abstract paper bib poster code slides
Complicated generative models often result in a situation where computing the likelihood of observed data is intractable, while simulating from the conditional density given a parameter value is relatively easy. Approximate Bayesian Computation (ABC) is a paradigm that enables simulation-based posterior inference in such cases by measuring the similarity between simulated and observed data in terms of a chosen set of summary statistics. However, there is no general rule to construct sufficient summary statistics for complex models. Insufficient summary statistics will "leak" information, which leads to ABC algorithms yielding samples from an incorrect (partial) posterior. In this paper, we propose a fully nonparametric ABC paradigm which circumvents the need for manually selecting summary statistics. Our approach, K2-ABC, uses maximum mean discrepancy (MMD) as a dissimilarity measure between the distributions over observed and simulated data. MMD is easily estimated as the squared difference between their empirical kernel embeddings. Experiments on a simulated scenario and a real-world biological problem illustrate the effectiveness of the proposed algorithm.@inproceedings{part_k2abc_2015_arxiv, author = {Park, Mijung and Jitkrittum, Wittawat and Sejdinovic, Dino}, title = {{K2-ABC}: Approximate {B}ayesian Computation with Infinite Dimensional Summary Statistics via Kernel Embeddings}, booktitle = {AISTATS}, year = {2016}, url = {http://jmlr.org/proceedings/papers/v51/park16.html}, wj_http = {http://jmlr.org/proceedings/papers/v51/park16.html}, wj_poster = {/assets/poster/k2abc_AISTATS2016_poster.pdf}, wj_code = {https://github.com/wittawatj/k2abc}, wj_slides = {/assets/talks/k2abc_AISTATS2016.pdf}, wj_highlight = {Oral presentation. 6.5\% of total submissions.} } -
Bayesian Manifold Learning: The Locally Linear Latent Variable Model NeurIPS 2015
abstract paper bib code slides
We introduce the Locally Linear Latent Variable Model (LL-LVM), a probabilistic model for non-linear manifold discovery that describes a joint distribution over observations, their manifold coordinates and locally linear maps conditioned on a set of neighbourhood relationships. The model allows straightforward variational optimisation of the posterior distribution on coordinates and locally linear maps from the latent space to the observation space given the data. Thus, the LL-LVM encapsulates the local-geometry preserving intuitions that underlie non-probabilistic methods such as locally linear embedding (LLE). Its probabilistic semantics make it easy to evaluate the quality of hypothesised neighbourhood relationships, select the intrinsic dimensionality of the manifold, construct out-of-sample extensions and to combine the manifold model with additional probabilistic models that capture the structure of coordinates within the manifold.@inproceedings{Park2015, author = {Park, Mijung and Jitkrittum, Wittawat and Qamar, Ahmad and Szab\'{o}, Zolt\'{a}n and Buesing, Lars and Sahani, Maneesh}, title = {Bayesian Manifold Learning: The Locally Linear Latent Variable Model}, booktitle = {NeurIPS}, year = {2015}, url = {http://arxiv.org/abs/1410.6791}, wj_http = {http://arxiv.org/abs/1410.6791}, wj_code = {https://github.com/mijungi/lllvm}, wj_slides = {/assets/talks/csml_lllvm.pdf} } -
Kernel-Based Just-In-Time Learning for Passing Expectation Propagation Messages UAI 2015
abstract paper bib poster code
We propose an efficient nonparametric strategy for learning a message operator in expectation propagation (EP), which takes as input the set of incoming messages to a factor node, and produces an outgoing message as output. This learned operator replaces the multivariate integral required in classical EP, which may not have an analytic expression. We use kernel-based regression, which is trained on a set of probability distributions representing the incoming messages, and the associated outgoing messages. The kernel approach has two main advantages: first, it is fast, as it is implemented using a novel two-layer random feature representation of the input message distributions; second, it has principled uncertainty estimates, and can be cheaply updated online, meaning it can request and incorporate new training data when it encounters inputs on which it is uncertain. In experiments, our approach is able to solve learning problems where a single message operator is required for multiple, substantially different data sets (logistic regression for a variety of classification problems), where it is essential to accurately assess uncertainty and to efficiently and robustly update the message operator.@inproceedings{jitkrittum_kernel-based_2015, title = {Kernel-Based Just-In-Time Learning for Passing Expectation Propagation Messages}, author = {Jitkrittum, Wittawat and Gretton, Arthur and Heess, Nicolas and Eslami, S. M. Ali and Lakshminarayanan, Balaji and Sejdinovic, Dino and Szab\'{o}, Zolt\'{a}n}, url = {http://arxiv.org/abs/1503.02551}, booktitle = {UAI}, year = {2015}, wj_http = {http://arxiv.org/abs/1503.02551}, wj_poster = {/assets/poster/kjit_uai2015_poster.pdf}, wj_code = {https://github.com/wittawatj/kernel-ep} } -
Performance of synchrony and spectral-based features in early seizure detection: exploring feature combinations and effect of latency International Workshop on Seizure Prediction (IWSP) 2015: Epilepsy Mechanisms, Models, Prediction and Control 2015
@misc{adam+al:2015:iwsp7, author = {Adam, Vincent and Soldado-Magraner, Joana and Jitkrittum, Wittawat and Strathmann, Heiko and Lakshminarayanan, Balaji and Ialongo, Alessandro Davide and Bohner, Gergo and Huh, Ben Dongsung and Goetz, Lea and Dowling, Shaun and Serban, Iulian Vlad and Louis, Matthieu}, title = {Performance of synchrony and spectral-based features in early seizure detection: exploring feature combinations and effect of latency}, booktitle = {International Workshop on Seizure Prediction (IWSP) 2015: Epilepsy Mechanisms, Models, Prediction and Control}, year = {2015}, wj_http = {http://www.iwsp7.org/}, wj_code = {https://github.com/vincentadam87/gatsby-hackathon-seizure} } -
High-Dimensional Feature Selection by Feature-Wise Kernelized Lasso Neural Computation 2014The goal of supervised feature selection is to find a subset of input features that are responsible for predicting output values. The least absolute shrinkage and selection operator (Lasso) allows computationally efficient feature selection based on linear dependency between input features and output values. In this letter, we consider a feature-wise kernelized Lasso for capturing nonlinear input-output dependency. We first show that with particular choices of kernel functions, nonredundant features with strong statistical dependence on output values can be found in terms of kernel-based independence measures such as the Hilbert-Schmidt independence criterion. We then show that the globally optimal solution can be efficiently computed; this makes the approach scalable to high-dimensional problems. The effectiveness of the proposed method is demonstrated through feature selection experiments for classification and regression with thousands of features.
@article{YamadaJSXS14, author = {Yamada, Makoto and Jitkrittum, Wittawat and Sigal, Leonid and Xing, Eric P. and Sugiyama, Masashi}, title = {High-Dimensional Feature Selection by Feature-Wise Kernelized Lasso}, journal = {Neural Computation}, volume = {26}, number = {1}, year = {2014}, pages = {185-207}, url = {http://www.mitpressjournals.org/doi/abs/10.1162/NECO_a_00537#.U9O7Idtsylg}, wj_http = {http://www.mitpressjournals.org/doi/abs/10.1162/NECO_a_00537#.U9O7Idtsylg}, wj_code = {http://www.makotoyamada-ml.com/hsiclasso.html} } -
Feature Selection via L1-Penalized Squared-Loss Mutual Information IEICE Transactions 2013Feature selection is a technique to screen out less important features. Many existing supervised feature selection algorithms use redundancy and relevancy as the main criteria to select features. However, feature interaction, potentially a key characteristic in real-world problems, has not received much attention. As an attempt to take feature interaction into account, we propose L1-LSMI, an L1-regularization based algorithm that maximizes a squared-loss variant of mutual information between selected features and outputs. Numerical results show that L1-LSMI performs well in handling redundancy, detecting non-linear dependency, and considering feature interaction.
@article{Jitkrittum2013, author = {Jitkrittum, Wittawat and Hachiya, Hirotaka and Sugiyama, Masashi}, title = {Feature Selection via L1-Penalized Squared-Loss Mutual Information}, journal = {IEICE Transactions}, year = {2013}, volume = {96-D}, pages = {1513-1524}, number = {7}, wj_pdf = {http://wittawat.com/pages/files/L1LSMI.pdf}, wj_code = {https://github.com/wittawatj/l1lsmi} } -
Squared-loss Mutual Information Regularization: A Novel Information-theoretic Approach to Semi-supervised Learning ICML 2013We propose squared-loss mutual information regularization (SMIR) for multi-class probabilistic classification, following the information maximization principle. SMIR is convex under mild conditions and thus improves the nonconvexity of mutual information regularization. It offers all of the following four abilities to semi-supervised algorithms: Analytical solution, out-of-sample/multi-class classification, and probabilistic output. Furthermore, novel generalization error bounds are derived. Experiments show SMIR compares favorably with state-of-the-art methods.
@inproceedings{Niu2013, author = {Niu, Gang and Jitkrittum, Wittawat and Dai, Bo and Hachiya, Hirotaka and Sugiyama, Masashi}, title = {Squared-loss Mutual Information Regularization: A Novel Information-theoretic Approach to Semi-supervised Learning}, booktitle = { ICML}, year = {2013}, volume = {28}, pages = {10-18}, url = {http://jmlr.org/proceedings/papers/v28/niu13.pdf}, wj_pdf = {http://jmlr.org/proceedings/papers/v28/niu13.pdf}, wj_code = {https://github.com/wittawatj/smir} } -
QAST: Question Answering System for Thai Wikipedia Proceedings of the 2009 Workshop on Knowledge and Reasoning for Answering Questions 2009We propose an open-domain question answering system using Thai Wikipedia as the knowledge base. Two types of information are used for answering a question: (1) structured information extracted and stored in the form of Resource Description Framework (RDF), and (2) unstructured texts stored as a search index. For the structured information, SPARQL transformed query is applied to retrieve a short answer from the RDF base. For the unstructured information, keyword-based query is used to retrieve the shortest text span containing the questions’s key terms. From the experimental results, the system which integrates both approaches could achieve an average MRR of 0.47 based on 215 test questions.
@inproceedings{Jitkrittum2009, author = {Jitkrittum, Wittawat and Haruechaiyasak, Choochart and Theeramunkong, Thanaruk}, title = {{QAST}: Question Answering System for {Thai} Wikipedia}, booktitle = {Proceedings of the 2009 Workshop on Knowledge and Reasoning for Answering Questions}, year = {2009}, series = {KRAQ '09}, pages = {11--14}, publisher = {Association for Computational Linguistics}, url = {http://dl.acm.org/citation.cfm?id=1697288.1697291}, wj_http = {http://dl.acm.org/citation.cfm?id=1697288.1697291} } -
Implementing News Article Category Browsing Based on Text Categorization Technique Web Intelligence/IAT Workshops 2008We propose a feature called category browsing to enhance the full-text search function of Thai-language news article search engine. The category browsing allows users to browse and filter search results based on some predefined categories. To implement the category browsing feature, we applied and compared among several text categorization algorithms including decision tree, Naive Bayes (NB) and Support Vector Machines (SVM). To further increase the performance of text categorization, we performed evaluation among many feature selection techniques including document frequency thresholding (DF), information gain (IG) and x2 (CHI). Based on our experiments using a large news corpus, the SVM algorithm with the IG feature selection yielded the best performance with the F1 measure equal to 95.42%.
@inproceedings{Haruechaiyasak2008, author = {Haruechaiyasak, Choochart and Jitkrittum, Wittawat and Sangkeettrakarn, Chatchawal and Damrongrat, Chaianun}, title = {Implementing News Article Category Browsing Based on Text Categorization Technique}, booktitle = {Web Intelligence/IAT Workshops}, year = {2008}, pages = {143-146}, ee = {http://dx.doi.org/10.1109/WIIAT.2008.61}, wj_http = {http://dx.doi.org/10.1109/WIIAT.2008.61} } -
Proximity-Based Semantic Relatedness Measurement on Thai Wikipedia International Conference on Knowledge, Information and Creativity Support Systems (KICSS) 2008
@inproceedings{proximity2008, author = {Jitkrittum, Wittawat and Theeramunkong, Thanaruk and Haruechaiyasak, Choochart}, title = {Proximity-Based Semantic Relatedness Measurement on {Thai} {Wikipedia}}, booktitle = {International Conference on Knowledge, Information and Creativity Support Systems (KICSS)}, year = {2008} } -
Managing Offline Educational Web Contents with Search Engine Tools International Conference on Asian Digital Libraries 2007In this paper, we describe our ongoing project to help alleviate the digital divide problem among high schools in rural areas of Thailand. The idea is to select, organize, index and distribute useful educational Web contents to schools where the Internet connection is not available. These Web contents can be used by teachers and students to enhance the teaching and learning for many class subjects. We have collaborated with a group of teachers from different high schools in order to gather the requirements for designing our software tools. One of the challenging issues is the variation in computer hardwares and network configuration found in different schools. Some shools have PCs connected to the school’s server via the Local Area Network (LAN). While some other schools have low-performance PCs without any network connection. To support both cases, we provide two solutions via two different search engine tools. These tools support content administrators, e.g., teachers, with the features to organize and index the contents. The tools also provide general users with the features to browse and search for needed information. Since the contents and index are locally stored on hard disk or some removable media such as CD-ROM, the Internet connection is not needed.
@inproceedings{Haruechaiyasak2007, author = {Haruechaiyasak, Choochart and Sangkeettrakarn, Chatchawal and Jitkrittum, Wittawat}, title = {Managing Offline Educational Web Contents with Search Engine Tools}, booktitle = {International Conference on Asian Digital Libraries}, year = {2007}, pages = {444-453}, ee = {http://dx.doi.org/10.1007/978-3-540-77094-7_56}, wj_http = {http://dx.doi.org/10.1007/978-3-540-77094-7_56} }